
S3GSecurity: A Simple Modern Successful Tech Stack
A while ago I was asked by a friend (Corey Pritchard) at work to evaluate his application during beta testing to see if there was any problems. Noting a few small technical issues I ran into, it was technically sound. We talked about it for a while after that, and fast forward a year later and we have been working on this same project together ever since.
S3G security is a training platform LMS (Learning Management System) that provides a business to business model to help train their employees on how to handle an active shooter situation. The course was architected by Jim Warwick, who has traveled across the United States providing different institutions with in-person training.
Today I’m going to be discussing the small, but insanely powerful stack implemented under the hood on how we keep this website online with a 99.9% uptime.
Requirements Engineering:
Good software engineers cannot underestimate the power of communication with the customer, so let’s talk some Requirements Engineering.
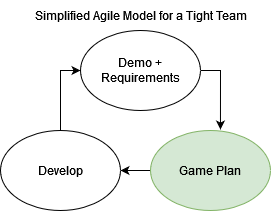
A Modern Sleek Agile Model
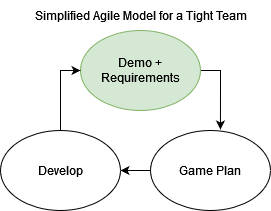
Let’s not overcomplicate things, it’s a small team.
Every week Corey meets with Jim to discuss new features and to live demo current features in development or testing. This is one of the coolest parts to me. Corey will ask about wording and styling of pages and change them on the fly for Jim, completely different relaxed feel from a typical customer demo. I wish more companies interactions with their clients were nearly as relaxed. Before we continue, let’s mention some core concepts of this application:
Some Large Responsibilities of the Application:
- The application will have 3 primary user-facing roles. A “user” role who will be watching the videos and taking the training. A “management” role” for employers to keep track of whether users have completed their training, and an administrator role for Jim and his company to have complete control over the application and adjust as needed.
- The application will provided tracking of a video to the user role that will record whether or not the user has seen the videos in the training. The application will also quiz the user at the end of every video.
Requirements Level Tools
Gitlab is exclusively used to maintain all issues, and feature tracking. It’s important to not over complicate this step. The entire concept of requirements tracking boils down to a few simple core details:
- Effectively communicate requirements clearly to your team and the customers so everything is clear.
- Transparantly give deadline estimates - and be clear when estimates are falling behind or not tracking.
- Appropriately coordinate with customers with alternative viable options to accomplish their ultimate goals.
It’s simple, so keep it simple. This is exactly what gitlab’s issue tracking offers, it’s all integrated with the development work flow so if you don’t need (and no one should) detailed metric tracking, you can ignore the concept. All that matters when you work with a customer is time estimates, money, and the features.
The Company Stack
When Corey first started he evaluated many different products on the market to come up with the most integrated approach to development. We both have worked at companys where this is an oversight: and you end up with 3 or four different poorly integrated developer tools that don’t synchronize effectively. The primary goal was to avoid this and make it so everything you need is in one spot while also being cost effective for his company.
| Concept | Implementation |
|---|---|
| Source Control | Gitlab |
| Issue and Feature Tracking | Gitlab |
| Deployments | Gitlab |
| Cloud architecture | Fully Google Cloud (GCP) |
Developer Level
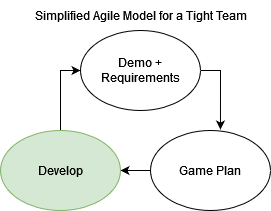
Since S3Gs inception Corey has developed it with future developers in mind, which has made on-boarding simple. Let’s talk about the moving parts and what they mean to a Software Engineer:
Backend
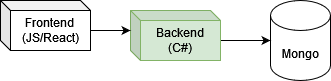
When I present architectures, I like to start at the micro / software development level and work my way out, so I will be referencing the same pieces and we will work our way towards a macro scope of our full project
C# is used as the backing language: starting in .net 6 and recently is in .net 7. The C# service is simple, effectively acting as a CRUD with fancy handling on the backend with a backing Mongo database.
The Mongo integration is code-first. Providing the developers with the flexibility of adjusting the relatively simple models and collections overtime to accommodate the agile interactions he has with Jim. When a model needs to be altered a simple code change occurs. Each change to the code driven models is evaluated to be backwards compatible so as not to break the deployment. It will be discussed how breaking changes are handled during the deployment section.
Front End
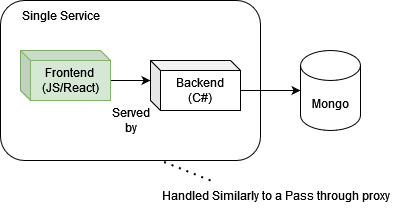
The User Interface is a generated with React following their more modern functional programming dialect. The front end used to be decoupled from the backend, where requests are simply forward to the backend with a standard pass through reverse proxy that is integrated into the startup of the app. The point of this was an attempt to scale one of them in deployment but not the other. This was found to be relatively pointless as the load of the user interface was negligible during performance testing. The two (backend and front end) therefore are served together using SPA so only one docker container is used in production to maintain the front and backend.
Testing
The backend is tested using XUnit, a standard testing framework for .net core. There is 95% code coverage at the time of writing. When a feature is written it is a requirement to maintain coverage before it is submitted.
The front end is unit tested minimally. Instead integration tests exists that cover the flow of the backend to front end using an awesome page object model integration that Selenium now provides. Most modern e2e frameworks are moving towards this paradigm.
The lack of unit tests in the UI is a hot topic in the agile world. Your standard young software engineer would likely scoff at the thought of no unit tests in the user interface. When I was an intern it was a standard practice to slap some generic tests around your pages using Jest or Jasmine to make sure the UI is functioning as intended. But there really is no crazy logic going on, the logic is bound to the roles. This article will not go into too deep a dive on why I believe they (UI based tests) are an artifact of simple claiming a higher code coverage, but rest assured the core of the application is tested through the integration tests.
Primary Backing Third Party Software
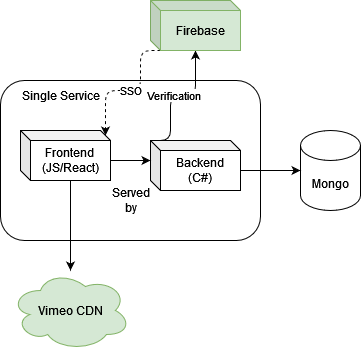
- Auth
Firebase is used to keep track of authentication and authorization, this is because the stack is google cloud, roughly most user federations and SSO providers do the same thing so the choice isn’t complicated here. We simple go with what the stack supplies.
- Video provider
Many video servicing softwares were evaluated during initial development. Ultimately the winner due to feature support was Vimeo. The primary downside to Vimeo is under the hood is has some whacky calls to it’s underlying CDN (content distribution network) that look like garbage. So we have to give the customers a whitelist for Vimeo specifically.
- Theming
The theme is a third party supplied item built on-top of material ui. Branding and logo were all developers in-house, and the color palette is chosen based on the branding, everything else is built off the initial theme. Designing based on this prebuilt theme gave a solid foundation where theming and styling was never a concern during development. I would recommend this for any small company. UX development can be easy, but often incredibly tedious unless you live and breath the stuff. Simply choose a branding and stick with it. The important part is to make sure all subcomponents you import inherit from your theme, keep the experience consistent, and don’t retheme every page.
These are the big ones (in my opinion) worth nothing. There are many smaller components that are used but have a smaller impact on the overall application.
Devops
As we have evolved our code base overtime, all of the features of gitlab have been fully unlocked. If you start your projects by using the full toolkit available to you, your life will be made easier overall. This is the methodology that we move forward with as we build and add more features to S3G.
Continuous Integration
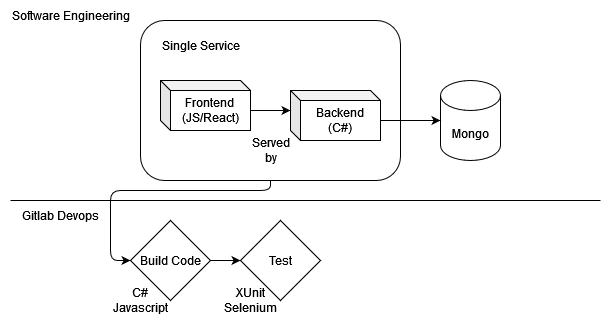
Gitlab pipelines are leveraged for the build process. Each commit kicks off a multi stage process for build, testing, dockerizing,scanning, and an optional deployment. Displayed above are the first steps in the pipeline process.
Leveraging all features of Gitlab
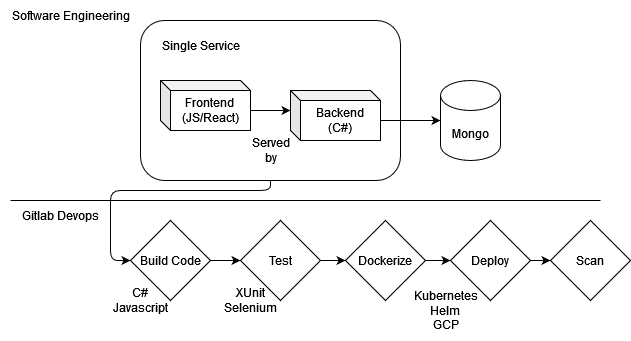
And here are the remaining steps.
Continuous Deployments
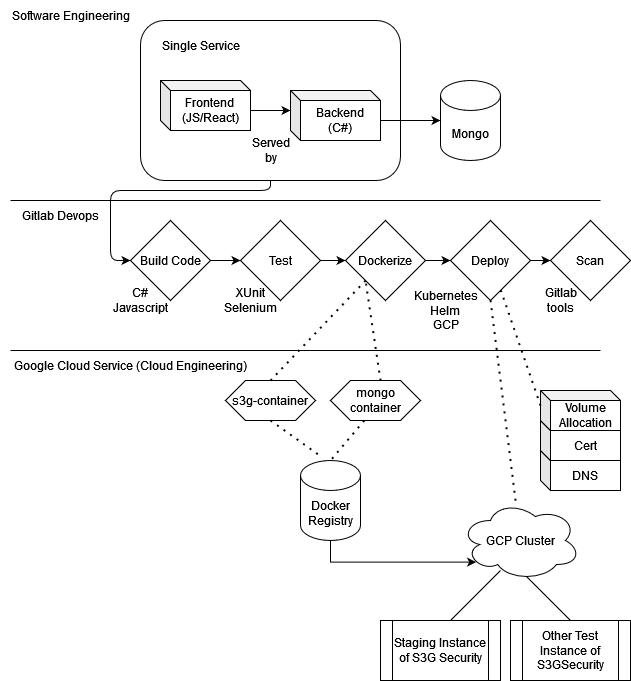
Integration with GCP
The docker containers are pushed to GCP in a private store associated with our account. We then have a helm chart in this single repository that contains the the configuration for how to orchestrate the deployment. The optional deployment uses the branch name slug as the subdomain and it is attached to the wildcard root domain. This domain is requested from google and is usually generated within a few seconds, however a dynamically generated certificate is requested from google that is slower. It takes roughly 30 minutes to provision. This is the only limitation we’ve run into for GCP since they don’t have wildcard certificates. The deployment is triggered through a manual step and this is used to verify features during our reviews and quality assurance testing. DAST scans are optionally applied after this manual step.
Dynamic Domain Provisioning
The deployment takes place using a helm chart. The modifications happen dynamically from some clever usages of integrated environment variables in gitlab. For these QA deployments the build is locked so you need a dynamically generated user and password to get in (in the event a crawler is trying to route to our private QA deployment). This is also done with some clever helm magic.
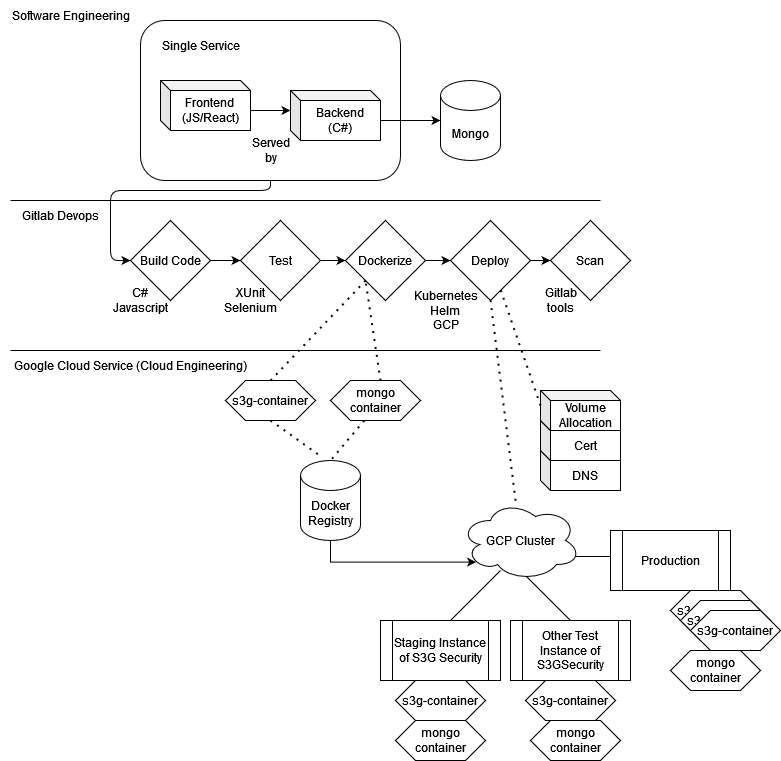
Production
Production deployments are done manually to prevent automation catastrophe. But the process is simple. We simply perform a helm upgrade on the production branch with the production gcp configuration. A tear down has never occurred. At the time of writing I believe it is on helm revision 60, all that happens is a simple chart change followed by the typical blue green deployment helm provides. There is no need to over engineer an application like this with canary or some other complicated deployment strategy at the time of writing since the customer base is all on the east coast. Deployments can be timed appropriately.
In the event a catastrophe or a db migration script must be run, an alternative deployment configuration exists by toggling a helm deployment variable (the 0.01% downtime). This fails over to a simple static web page which displays a maintenance message while we work on the hot fix or db migration.
Additionally, every day a backup is made of all data and stored in the event a disaster recovery needs to occur, this is a simple toggle in GCP.
Scaling Scope and Load Balancing
The application scope and load should always be determined by how the clientele will be using the application. GCP provide automatic DOS prevention, so this will be ignored when considering scaling parameters. The way our application will mostly work is a very low load day to day with intermittent massive spikes of network traffic from customers.
The highest portion of bandwidth is not delivered by our content, that would be Vimeos CDN. Instead our content is all lightweight json from loading our pages. Our clients have at most had a thousand or so on at once. We were able to load test spikes of several thousand at a time with no crazy amount of cpu or memory usage.
So it is likely we would not need to scale. Regardless, the deployment in production is scaled out so that 3 pods are running at once the standard round robin since least load in our case would be next to useless.
As our customer base has grown we have been monitoring cpu and memory usage, however it is never enough that we have considered a dedicated load balancing solution.
Thus our final Diagram:
Conclusion
The scope of this architecture is to help budding startups and smaller companies realize how much you can get done with a minimal team. This application has been developed over the course of 3.5 years to publishing and has a generous number of clients. If your architecture is simple from the start, you are setting yourself up for success. Shortcuts can be taken when your team is properly experienced, and nothing ever has to be “by-the-book”. This is an architecture that has worked for us, and has been relatively cost-effective when considering the full scope of the application and revenue.
Comments